Monitor setup considerations
It’s essential to balance coverage and signal-to-noise ratio. While maximal monitoring across the stack may be appealing, it is not always the best option. It can cause alert fatigue and wear out your data team, causing important issues to be overlooked. The right monitor placement strategy can help with this. We’ve written extensively about how to best set up your monitoring in the Data Product’s guide. Here are a few guidelines.Designing a Testing Strategy
A well-structured testing strategy ensures comprehensive coverage across the data platform while minimizing redundancy. This involves defining testing approaches for each layer—sources, transformations, and data products—and considering how transformation layer tests (from dbt, SQLMesh, or Coalesce Transform) complement anomaly monitors to avoid redundant testing.Testing Sources
Testing at the source layer is critical because errors propagate downstream. Since this layer has the most dependencies, a strong foundation reduces the need for excessive testing further down the pipeline. See more in the Testing sources section of our guide.Testing Transformations
Once sources are well-tested, transformation testing can focus on verifying changes rather than duplicating checks already performed upstream. This includes validating logic and aggregations after joins. A targeted approach ensures transformations produce accurate and reliable results without unnecessary overhead. See more in the Testing transformations section in our guideTesting Data Products
Data product testing should be targeted and ideally done by data people with the relevant domain expertise. Instead of focusing on technical aspects of data, when testing data products, you should verify the logic encoded in SQL transformations. See more in the Testing products section of our guide.Setting up monitors
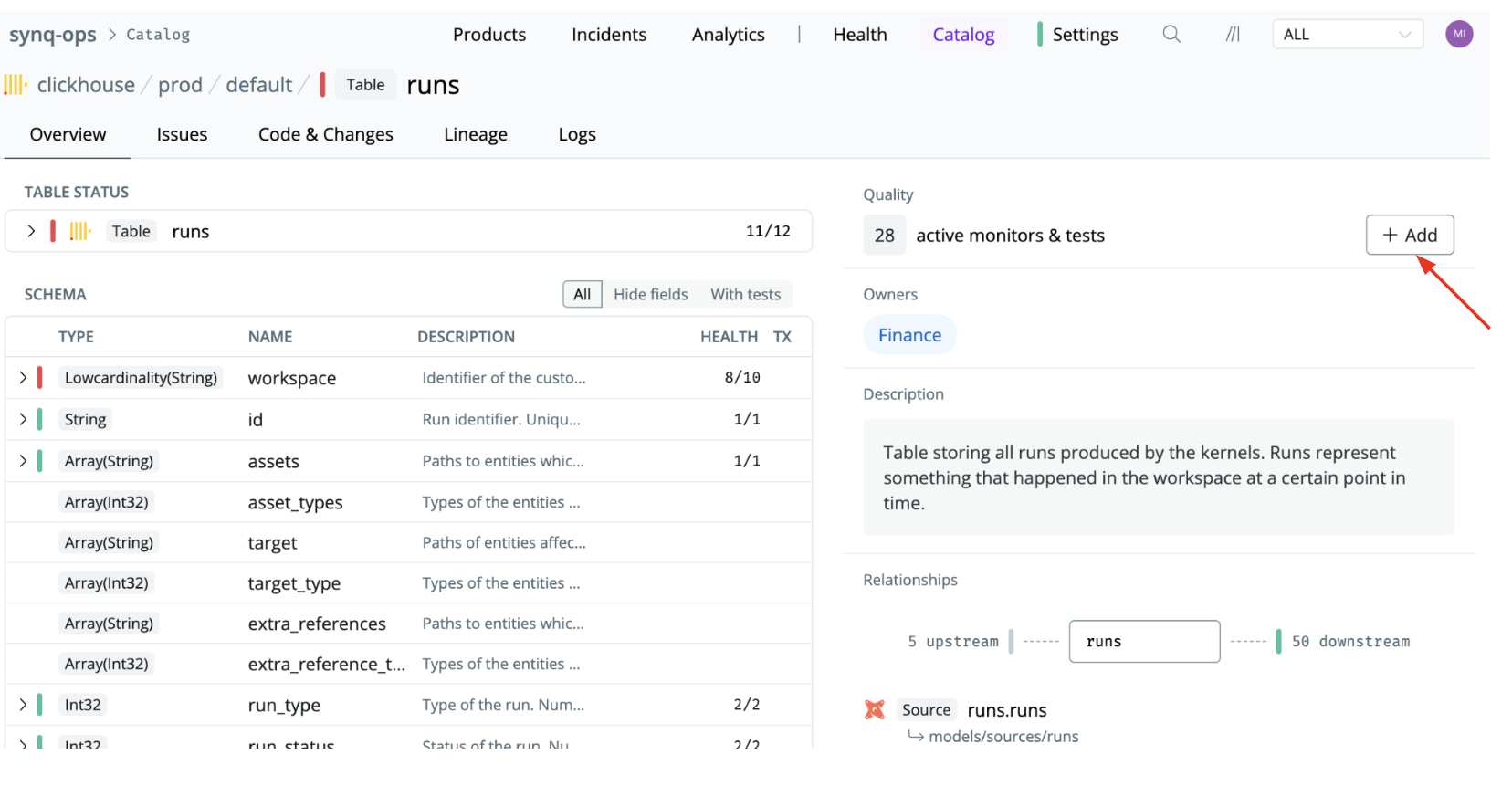
There are two ways to set up monitors.1. Add a monitor to an individual table
Set up monitors one table at a time. This is great for targeted monitoring where you just want to monitor specific tables. It’s also the only way to define custom monitors.- Navigate to the table or data model (e.g., by using the Catalog or Search functionality)
- Click the
+Addbutton and select a monitor type