This guide will walk you through how to create a service token and set up the relevant configurations for your dbt Cloud projectWe need this information so we can connect to dbt and extract metadata such as runs and test failures. We only request read access to your metadata and won’t be able to read raw data or update or run any models.In order to be able to finish this guide you’ll need:
→ Access to dbt cloud
→ Having been assigned the owner role in dbt cloud⏱️ Estimated time to finish: 10 minutes.
→ Access to dbt cloud
→ Having been assigned the owner role in dbt cloud⏱️ Estimated time to finish: 10 minutes.
Name your integration
For exampledbt cloud
Set the API endpoint
The dbt Cloud default region is in the US but if you’re on the enterprise plan you can host your project in a different region. Select the region where your dbt Cloud project is hosted- Production (US): https://cloud.getdbt.com (default)
- Production (Europe): https://emea.dbt.com
- Production (AU): https://au.dbt.com
Generate a token
These steps will take you through how to create a token you can use to manage Coalesce Quality access to your dbt Cloud project
- Open dbt cloud and go to Account Settings in the menu bar
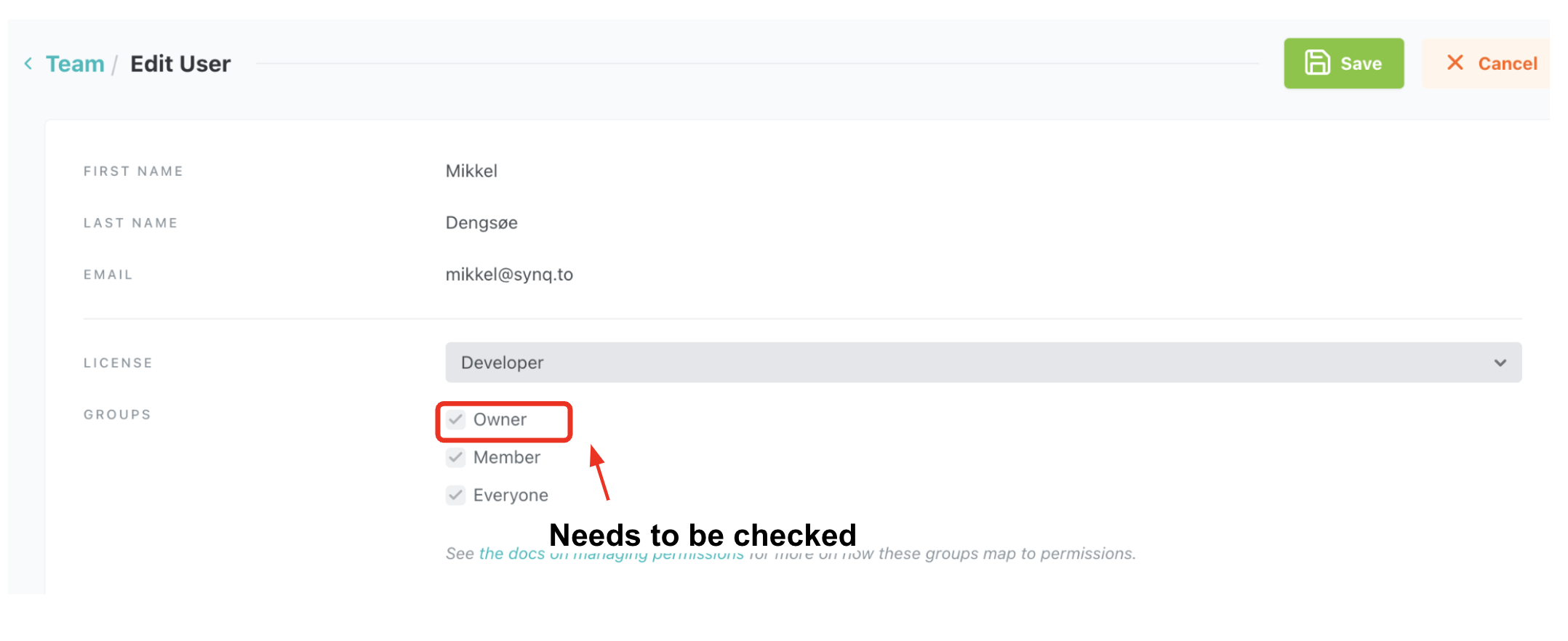
- If you don’t see this option in the sidebar you don’t have the right dbt permission. If this is the case, either ask your dbt admin to make you an Owner (expand to see how) or ask the dbt admin to complete the steps in this guide
- Click Service Tokens
- Create New Token
- Name your token
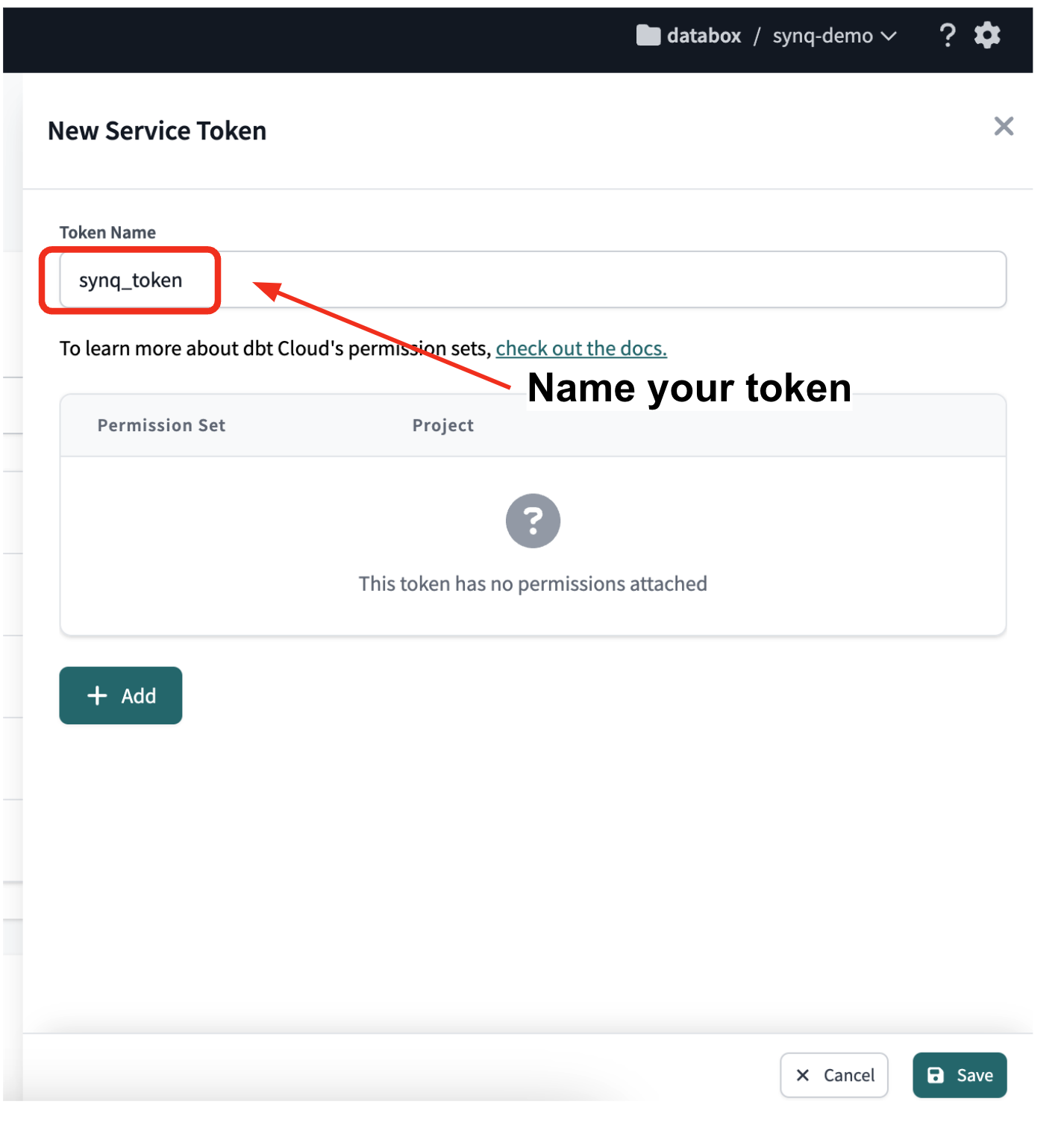
- Click Add to add a new permission
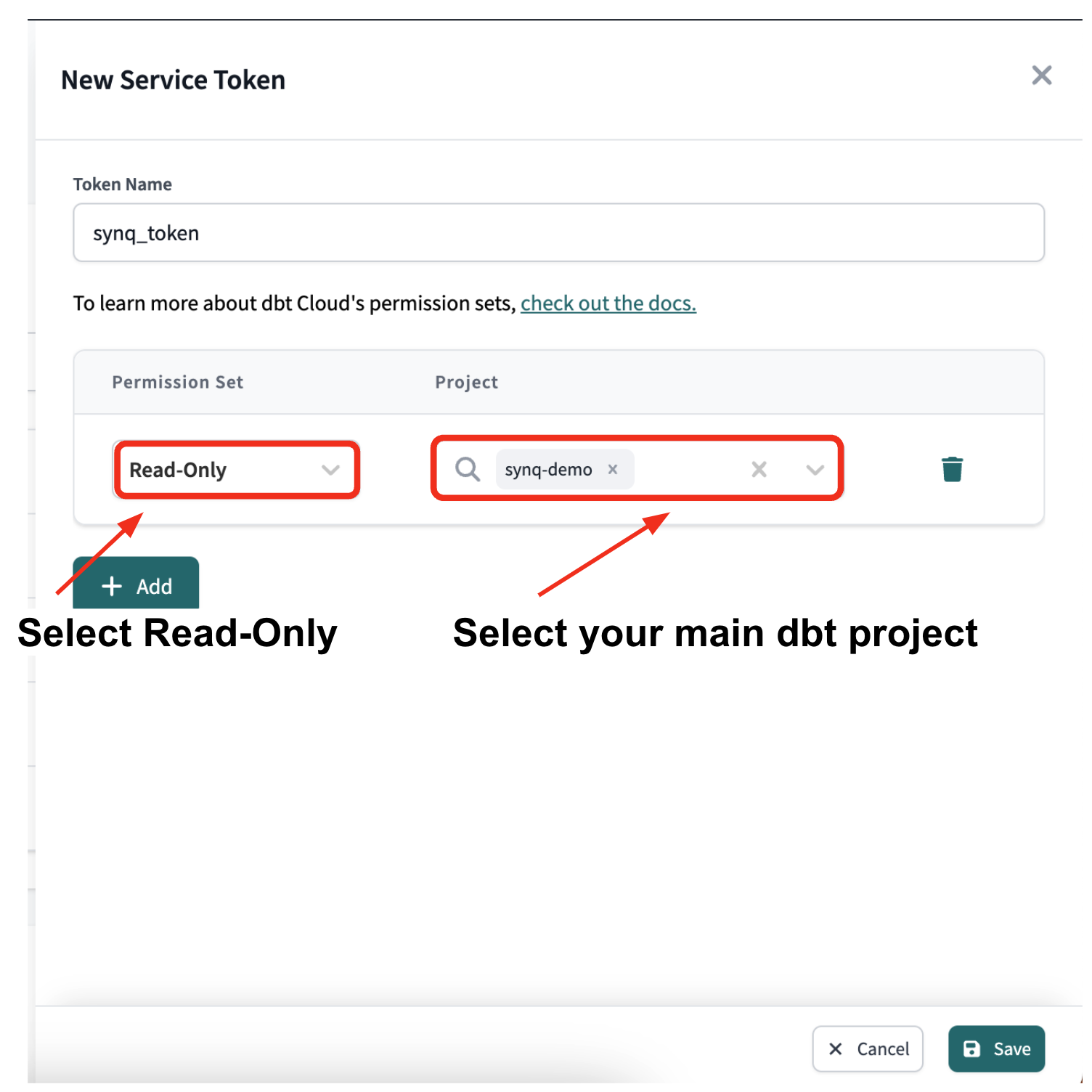
- Set permissions
Permission Setshould be set to Read-Only. This will let Coalesce Quality read your dbt logsProjectshould be set to your main dbt project. If you want to integrate multiple projects, add all projects you want to integrate or set to All Projects
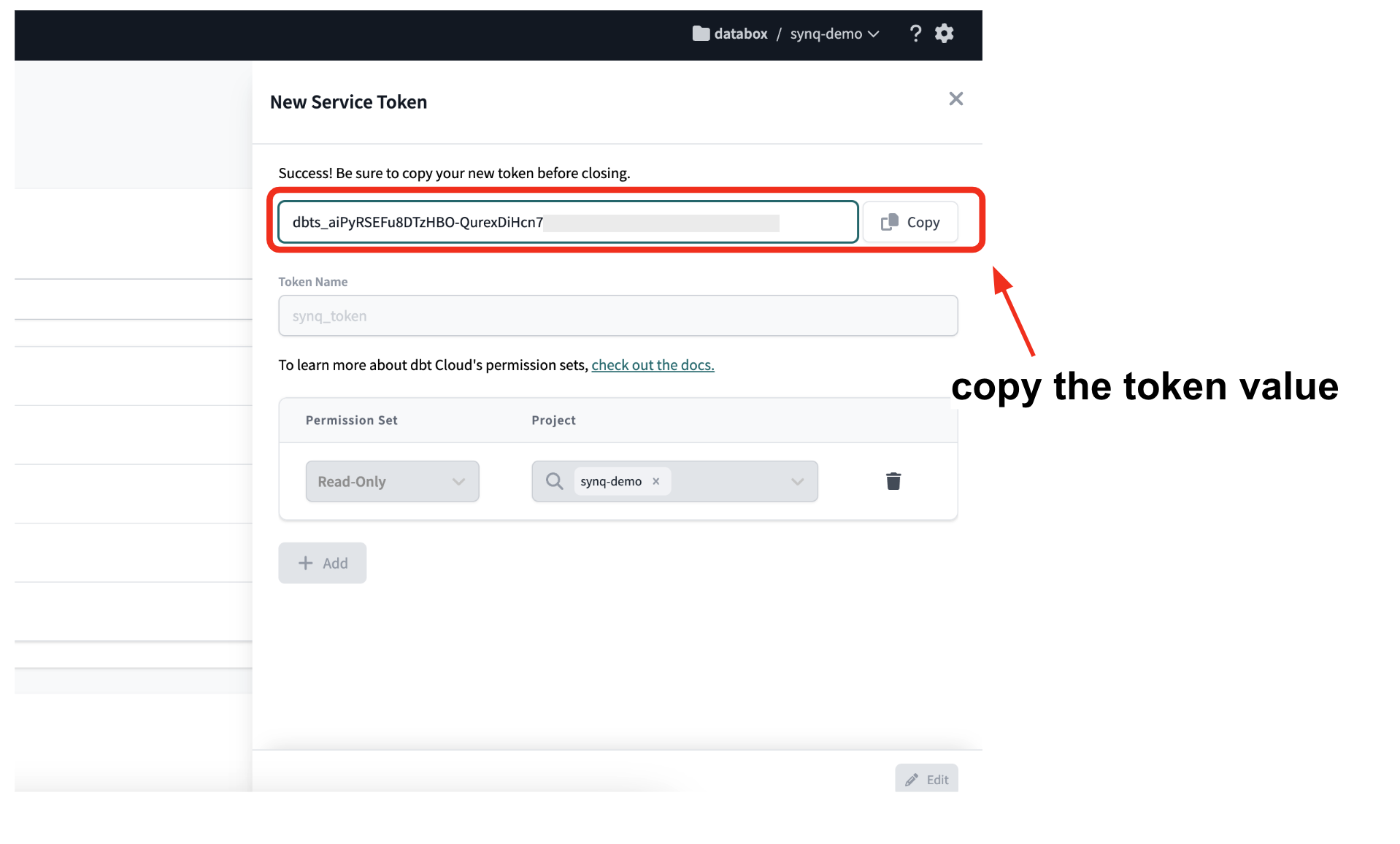
- Save the token
- Copy the token value
Select your dbt project
Choose your main dbt projectSelect the job(s) you want Coalesce Quality to monitor
You’ll most likely want to monitor your production and freshness job(s). Unless you have a good reason, we suggest you don’t monitor jobs such as CI, staging, or experimental jobsFAQ
What access do you require?
We only request read access to your metadata and won’t be able to read raw data or update or run any modelsWill you store personal or business-critical data
Coalesce Quality only stores log level data and doesn’t access any actual data from your data warehouseWhich artifacts are you collecting from dbt
We are collecting the following artifacts from dbt. For more information about dbt artifacts see this article- manifest.json — to understand the structure of the warehouse
- run_results.json — to see the status of executions
- catalog.json — to be able to provide catalog-like functionality
- Optionally sources.json — to capture dbt source freshness